Programma
De invloed van nieuwe database-technologie op data-architecturen
Kunnen we nog wel een technologie-onafhankelijke data-architectuur ontwikkelen? In deze sessie worden de unieke architecturen van de nieuwe technologieën op een rijtje gezet en hun mogelijke invloed op data-architecturen belicht.
Lees meer
Ooit gingen we uit van de regel dat data-architecturen onafhankelijk van technologieën en producten opgezet moesten worden; eerst de data-architectuur en dan de bijpassende producten uitzoeken. Dat lukte ook omdat veel producten redelijk uitwisselbaar was. Maar kan dat nog steeds? De laatste jaren worden we geconfronteerd met een niet aflatende stroom technologieën voor het verwerken, analyseren en opslaan van gegevens. Denk hierbij aan Hadoop, NoSQL, NewSQL, GPU-databases, Spark en Kafka. Deze technologieën hebben een grote invloed op data-verwerkende architecturen, zoals datawarehouses en streaming applicaties. Maar het belangrijkste is dat veel van deze producten zeer unieke interne architecturen hebben en direct bepaalde data-architecturen afdwingen. Dus kunnen we nog wel een technologie onafhankelijke data-architectuur ontwikkelen? In deze sessie worden de unieke architecturen van de nieuwe technologieën op een rijtje gezet en hun mogelijke invloed op data-architecturen belicht.
- Zitten we vast in onze oude ideeën over data-architectuur?
- Van generieke naar specialistische technologieën
- Voorbeelden van technologieën die een bepaalde data-architectuur afdwingen
- Wat is de rol van softwaregeneratoren bij deze discussie?
- Nieuwe technologie kan alleen optimaal gebruikt worden als de data-architectuur er op afgestemd is.
How Three Enterprises Turned Their Big Data into Their Biggest Asset
Organizations worldwide are facing the challenge of effectively analyzing their exponentially growing data stores. Most data warehouses were designed before the big data explosion, and struggle to support modern workloads. To make due, many companies are cutting down on their data pipelines, severely limiting the productivity of data professionals.
Lees meer
Organizations worldwide are facing the challenge of effectively analyzing their exponentially growing data stores. Most data warehouses were designed before the big data explosion, and struggle to support modern workloads. To make due, many companies are cutting down on their data pipelines, severely limiting the productivity of data professionals.
This session will explore the case studies of three organizations who used the power of GPU to broaden their queries, analyze significantly more data, and extract previously unobtainable insights.
Lees minderData Modelstorming: From Business Models to Analytical Models
In this lively session Lawrence Corr shares his favourite collaborative modeling techniques for successfully engaging stakeholders using BEAM and the Business Model Canvas for value-driven BI requirements gathering and star schema design.
Lees meer
Have you ever been disappointed with the results of traditional data requirements gathering, especially for BI and data analytics? Ever wished you could ‘cut to the chase’ and somehow model the data directly with the people who know it and want to use it. However, that’s not a realistic alternative, is it? Business people don’t do data modeling! But what if that wasn’t the case?
In this lively session Lawrence Corr shares his favourite collaborative modeling techniques – popularized in books such as ‘Business Model Generation’ and ‘Agile Data Warehouse Design’ – for successfully engaging stakeholders using BEAM (Business Event Analysis and Modeling) and the Business Model Canvas for value-driven BI requirements gathering and star schema design. Learn how visual thinking, narrative, 7Ws and lots of Post-it ™ notes can get your stakeholders thinking dimensionally and capturing their own data requirements with agility.
This session will cover:
- The whys of data modelstorming: Why it’s different from traditional data modeling and why we need it
- Drawing user-focused data models: alternatives to entity relation diagrams for visualising data opportunities
- Using BEAM (Business Event Analysis and Modeling) to discover key data sources and define rich data sets
- How making toast can encourage collaborative modeling within your organisation
- Modelstorming templates which you can download and start using straight away.
Het moderne database eco-systeem in een snel veranderende wereld
Cloud diensten, in-memory databases en database servers die gebruik maken van massive parallel processing voeren de boventoon in de marketing hype van vandaag. Maar wat is er de laatste tien jaar nu echt veranderd in de databasemarkt?
Lees meer
Cloud diensten, in-memory databases en database servers die gebruik maken van massive parallel processing voeren de boventoon in de marketing hype van vandaag. Maar wat is er de laatste tien jaar nu echt veranderd in de databasemarkt? Welke aanbieders zijn in staat om vooruit te blijven lopen op technologisch gebied? Moeten we ons zorgen maken over de invloed van nieuwe hardware zoals GPU en non-volatile memory? En kunnen we wel vertrouwen op programmeurs om keer op keer het wiel opnieuw uit te vinden voor elke database-interactie? Wat zijn de hot technologies in de labs van de database leveranciers?
In deze sessie zal vooral worden gekeken naar:
- Column stores, een de-facto standaard voor Business Intelligence, met haar oorsprong in Nederland
- Van Hadoop tot Apache Spark, wanneer u wel en wanneer u niet de portemonnee moet trekken
- Het slechten van de muren tussen het DBMS en programmeertalen als Java/C/..
- Performance, niet alleen een kwestie van een benchmark score
- Efficiënt omgaan met resources om geld te besparen.
Lunchpauze
Becoming Data Driven – A Data Strategy for Success & Business Insight
In order to transform into a data-driven, digitally based organisation, a plan which spells out what must be done to is required. This session will outline how to produce a data strategy and supporting roadmap, and how to ensure that it becomes a living and agile blueprint for change rather than a statement of aspiration.
Lees meer
More enterprises are seeking to transform themselves into data-driven, digitally based organisations. Many have recognised that this will not be solely achieved by acquiring new technologies and tools. Instead they are aware that becoming data-driven requires a holistic transformation of existing business models, involving culture change, process redesign and re-engineering, and a step change in data management capabilities.
To deliver this holistic transformation, creating and delivering a coherent and overarching data strategy is essential. Becoming data-driven requires a plan which spells out what an organisation must do to achieve its data transformational goals. A data strategy can be critical in answering questions such as: How ready are we to become data-driven? What data do we need to focus on, now and in the future? What problems and opportunities should we tackle first and why? What part does business intelligence and data warehousing have to play in a data strategy? How do we assess a data strategy’s success?
This session will outline how to produce a data strategy and supporting roadmap, and how to ensure that it becomes a living and agile blueprint for change rather than a statement of aspiration.
This session will cover:
- The relationship between an organisation’s business strategy and data strategy
- What a data strategy is (and is not)
- Building & delivering a data strategy – the key components and steps
- The role of BI/DW in a data strategy – data issues and data needs
- The ‘limit or liberate’ data dilemma and how to resolve it through data governance
- Several use cases of successful data strategies and lessons learned.
Model Deployment for Production & Adoption - Why the Last Task Should be the First Discussed
Most analytic modelers wait until after they’ve built a model to consider deployment. However, doing so practically ensures project failure. This session will convey imperative preparatory considerations to arrive at accountable, deployable and adoptable projects.
Lees meer
Most analytic modelers wait until after they’ve built a model to consider deployment. Doing so practically ensures project failure. Their motivations are typically sincere but misplaced. In many cases, analysts want to first ensure that there is something worth deploying. However, there are very specific design issues that must be resolved before meaningful data exploration, data preparation and modeling can begin. The most obvious of many considerations to address ahead of modeling is whether senior management truly desires a deployed model. Perhaps the perceived purpose of the model is insight and not deployment at all. There is a myth that a model that manages to provide insight will also have the characteristics desirable in a deployed model. It is simply not true. No one benefits from this lack of foresight and communication. This session will convey imperative preparatory considerations to arrive at accountable, deployable and adoptable projects and Keith will share carefully chosen project design case studies and how deployment is a critical design consideration.
- Which modeling approach continues to be the most common and important in machine learning
- The iterative process from exploration to modeling to deployment
- Which team members should be consulted in the earliest stages of predictive analytics project design?
- Misconceptions about predictive analytics, modeling, and deployment
- Costly strategic design errors to avoid in predictive analytics projects
- Common styles of deployment.
Implementatie en acceptatie van schaalbare Machine Learning oplossingen
Jan Veldsink legt uit hoe je de organisatie op orde kunt krijgen voor Machine Learning-projecten.
Lees meer
Jan Veldsink (Lead Artificial Intelligence en Cognitive Technologies bij Rabobank) legt uit hoe je de organisatie op orde kunt krijgen voor Machine Learning-projecten. In grote organisaties kan de toegang tot en het gebruik van alle juiste en relevante data een uitdaging zijn. In deze presentatie zal Jan uitleggen hoe de problemen die zich voordoen, kunnen worden opgelost en hoe de ontwikkelingscyclus kan worden georganiseerd, van development via testen tot in productie nemen. Ook zal hij laten zien hoe hij BigML heeft gebruikt en hoe de aanwezigen BigML in hun strategie kunnen inpassen. Mensen leren ook van voorbeelden, dus in dese sessie zal hij enkele van de successen en echte projecten laten zien op het gebied van voorkomen en oplossen van financiële criminaliteit.
Lees minderAgile Methods and Data Warehousing: How to Deliver Faster
Most people will agree that data warehousing and business intelligence projects take too long to deliver tangible results. This presentation will look at the 12 principles behind the Agile Manifesto and see how these approaches can be used to speed things up in the context of a data warehouse project.
Lees meer
Most people will agree that data warehousing and business intelligence projects take too long to deliver tangible results. Often by the time a solution is in place, the business needs have changed. With all the talk about Agile development methods like SCRUM and Extreme Programming, the question arises as to how these approaches can be used to deliver data warehouse and business intelligence projects faster. This presentation will look at the 12 principles behind the Agile Manifesto and see how they might be applied in the context of a data warehouse project. The goal is to determine a method or methods to get a more rapid (2-4 weeks) delivery of portions of an enterprise data warehouse architecture. Real world examples with metrics will be discussed.
- What are the original 12 principles of Agile
- How can they be applied to DW/BI projects
- Real world examples of successful application of the principles.
Borrel
Opening door de dagvoorzitter
De invloed van nieuwe database-technologie op data-architecturen
Kunnen we nog wel een technologie-onafhankelijke data-architectuur ontwikkelen? In deze sessie worden de unieke architecturen van de nieuwe technologieën op een rijtje gezet en hun mogelijke invloed op data-architecturen belicht.
Lees meer
Ooit gingen we uit van de regel dat data-architecturen onafhankelijk van technologieën en producten opgezet moesten worden; eerst de data-architectuur en dan de bijpassende producten uitzoeken. Dat lukte ook omdat veel producten redelijk uitwisselbaar was. Maar kan dat nog steeds? De laatste jaren worden we geconfronteerd met een niet aflatende stroom technologieën voor het verwerken, analyseren en opslaan van gegevens. Denk hierbij aan Hadoop, NoSQL, NewSQL, GPU-databases, Spark en Kafka. Deze technologieën hebben een grote invloed op data-verwerkende architecturen, zoals datawarehouses en streaming applicaties. Maar het belangrijkste is dat veel van deze producten zeer unieke interne architecturen hebben en direct bepaalde data-architecturen afdwingen. Dus kunnen we nog wel een technologie onafhankelijke data-architectuur ontwikkelen? In deze sessie worden de unieke architecturen van de nieuwe technologieën op een rijtje gezet en hun mogelijke invloed op data-architecturen belicht.
- Zitten we vast in onze oude ideeën over data-architectuur?
- Van generieke naar specialistische technologieën
- Voorbeelden van technologieën die een bepaalde data-architectuur afdwingen
- Wat is de rol van softwaregeneratoren bij deze discussie?
- Nieuwe technologie kan alleen optimaal gebruikt worden als de data-architectuur er op afgestemd is.
How Three Enterprises Turned Their Big Data into Their Biggest Asset
Organizations worldwide are facing the challenge of effectively analyzing their exponentially growing data stores. Most data warehouses were designed before the big data explosion, and struggle to support modern workloads. To make due, many companies are cutting down on their data pipelines, severely limiting the productivity of data professionals.
Lees meer
Organizations worldwide are facing the challenge of effectively analyzing their exponentially growing data stores. Most data warehouses were designed before the big data explosion, and struggle to support modern workloads. To make due, many companies are cutting down on their data pipelines, severely limiting the productivity of data professionals.
This session will explore the case studies of three organizations who used the power of GPU to broaden their queries, analyze significantly more data, and extract previously unobtainable insights.
Lees minderData Modelstorming: From Business Models to Analytical Models
In this lively session Lawrence Corr shares his favourite collaborative modeling techniques for successfully engaging stakeholders using BEAM and the Business Model Canvas for value-driven BI requirements gathering and star schema design.
Lees meer
Have you ever been disappointed with the results of traditional data requirements gathering, especially for BI and data analytics? Ever wished you could ‘cut to the chase’ and somehow model the data directly with the people who know it and want to use it. However, that’s not a realistic alternative, is it? Business people don’t do data modeling! But what if that wasn’t the case?
In this lively session Lawrence Corr shares his favourite collaborative modeling techniques – popularized in books such as ‘Business Model Generation’ and ‘Agile Data Warehouse Design’ – for successfully engaging stakeholders using BEAM (Business Event Analysis and Modeling) and the Business Model Canvas for value-driven BI requirements gathering and star schema design. Learn how visual thinking, narrative, 7Ws and lots of Post-it ™ notes can get your stakeholders thinking dimensionally and capturing their own data requirements with agility.
This session will cover:
- The whys of data modelstorming: Why it’s different from traditional data modeling and why we need it
- Drawing user-focused data models: alternatives to entity relation diagrams for visualising data opportunities
- Using BEAM (Business Event Analysis and Modeling) to discover key data sources and define rich data sets
- How making toast can encourage collaborative modeling within your organisation
- Modelstorming templates which you can download and start using straight away.
Het moderne database eco-systeem in een snel veranderende wereld
Cloud diensten, in-memory databases en database servers die gebruik maken van massive parallel processing voeren de boventoon in de marketing hype van vandaag. Maar wat is er de laatste tien jaar nu echt veranderd in de databasemarkt?
Lees meer
Cloud diensten, in-memory databases en database servers die gebruik maken van massive parallel processing voeren de boventoon in de marketing hype van vandaag. Maar wat is er de laatste tien jaar nu echt veranderd in de databasemarkt? Welke aanbieders zijn in staat om vooruit te blijven lopen op technologisch gebied? Moeten we ons zorgen maken over de invloed van nieuwe hardware zoals GPU en non-volatile memory? En kunnen we wel vertrouwen op programmeurs om keer op keer het wiel opnieuw uit te vinden voor elke database-interactie? Wat zijn de hot technologies in de labs van de database leveranciers?
In deze sessie zal vooral worden gekeken naar:
- Column stores, een de-facto standaard voor Business Intelligence, met haar oorsprong in Nederland
- Van Hadoop tot Apache Spark, wanneer u wel en wanneer u niet de portemonnee moet trekken
- Het slechten van de muren tussen het DBMS en programmeertalen als Java/C/..
- Performance, niet alleen een kwestie van een benchmark score
- Efficiënt omgaan met resources om geld te besparen.
Lunchpauze
Becoming Data Driven – A Data Strategy for Success & Business Insight
In order to transform into a data-driven, digitally based organisation, a plan which spells out what must be done to is required. This session will outline how to produce a data strategy and supporting roadmap, and how to ensure that it becomes a living and agile blueprint for change rather than a statement of aspiration.
Lees meer
More enterprises are seeking to transform themselves into data-driven, digitally based organisations. Many have recognised that this will not be solely achieved by acquiring new technologies and tools. Instead they are aware that becoming data-driven requires a holistic transformation of existing business models, involving culture change, process redesign and re-engineering, and a step change in data management capabilities.
To deliver this holistic transformation, creating and delivering a coherent and overarching data strategy is essential. Becoming data-driven requires a plan which spells out what an organisation must do to achieve its data transformational goals. A data strategy can be critical in answering questions such as: How ready are we to become data-driven? What data do we need to focus on, now and in the future? What problems and opportunities should we tackle first and why? What part does business intelligence and data warehousing have to play in a data strategy? How do we assess a data strategy’s success?
This session will outline how to produce a data strategy and supporting roadmap, and how to ensure that it becomes a living and agile blueprint for change rather than a statement of aspiration.
This session will cover:
- The relationship between an organisation’s business strategy and data strategy
- What a data strategy is (and is not)
- Building & delivering a data strategy – the key components and steps
- The role of BI/DW in a data strategy – data issues and data needs
- The ‘limit or liberate’ data dilemma and how to resolve it through data governance
- Several use cases of successful data strategies and lessons learned.
Model Deployment for Production & Adoption - Why the Last Task Should be the First Discussed
Most analytic modelers wait until after they’ve built a model to consider deployment. However, doing so practically ensures project failure. This session will convey imperative preparatory considerations to arrive at accountable, deployable and adoptable projects.
Lees meer
Most analytic modelers wait until after they’ve built a model to consider deployment. Doing so practically ensures project failure. Their motivations are typically sincere but misplaced. In many cases, analysts want to first ensure that there is something worth deploying. However, there are very specific design issues that must be resolved before meaningful data exploration, data preparation and modeling can begin. The most obvious of many considerations to address ahead of modeling is whether senior management truly desires a deployed model. Perhaps the perceived purpose of the model is insight and not deployment at all. There is a myth that a model that manages to provide insight will also have the characteristics desirable in a deployed model. It is simply not true. No one benefits from this lack of foresight and communication. This session will convey imperative preparatory considerations to arrive at accountable, deployable and adoptable projects and Keith will share carefully chosen project design case studies and how deployment is a critical design consideration.
- Which modeling approach continues to be the most common and important in machine learning
- The iterative process from exploration to modeling to deployment
- Which team members should be consulted in the earliest stages of predictive analytics project design?
- Misconceptions about predictive analytics, modeling, and deployment
- Costly strategic design errors to avoid in predictive analytics projects
- Common styles of deployment.
Implementatie en acceptatie van schaalbare Machine Learning oplossingen
Jan Veldsink legt uit hoe je de organisatie op orde kunt krijgen voor Machine Learning-projecten.
Lees meer
Jan Veldsink (Lead Artificial Intelligence en Cognitive Technologies bij Rabobank) legt uit hoe je de organisatie op orde kunt krijgen voor Machine Learning-projecten. In grote organisaties kan de toegang tot en het gebruik van alle juiste en relevante data een uitdaging zijn. In deze presentatie zal Jan uitleggen hoe de problemen die zich voordoen, kunnen worden opgelost en hoe de ontwikkelingscyclus kan worden georganiseerd, van development via testen tot in productie nemen. Ook zal hij laten zien hoe hij BigML heeft gebruikt en hoe de aanwezigen BigML in hun strategie kunnen inpassen. Mensen leren ook van voorbeelden, dus in dese sessie zal hij enkele van de successen en echte projecten laten zien op het gebied van voorkomen en oplossen van financiële criminaliteit.
Lees minderAgile Methods and Data Warehousing: How to Deliver Faster
Most people will agree that data warehousing and business intelligence projects take too long to deliver tangible results. This presentation will look at the 12 principles behind the Agile Manifesto and see how these approaches can be used to speed things up in the context of a data warehouse project.
Lees meer
Most people will agree that data warehousing and business intelligence projects take too long to deliver tangible results. Often by the time a solution is in place, the business needs have changed. With all the talk about Agile development methods like SCRUM and Extreme Programming, the question arises as to how these approaches can be used to deliver data warehouse and business intelligence projects faster. This presentation will look at the 12 principles behind the Agile Manifesto and see how they might be applied in the context of a data warehouse project. The goal is to determine a method or methods to get a more rapid (2-4 weeks) delivery of portions of an enterprise data warehouse architecture. Real world examples with metrics will be discussed.
- What are the original 12 principles of Agile
- How can they be applied to DW/BI projects
- Real world examples of successful application of the principles.
Borrel
Opening door de dagvoorzitter
Addressing Organizational Resistance to Predictive Analytics and Machine Learning
Many who work within organizations that are in the early stages of their digital transformation are surprised when an accurate model faces organizational resistance. Keith will share case studies based upon real world projects that reveal why organizational resistance was a problem and how it was addressed.
Lees meer
Many who work within organizations that are in the early stages of their digital transformation are surprised when an accurate model — built with good intentions and capable of producing measurable benefit to the organization — faces organizational resistance. No veteran modeler is surprised by this because all projects face some organizational resistance to some degree. This predictable and eminently manageable problem simply requires attention during the project’s design phase. Proper design will minimize resistance and most projects will proceed to their natural conclusion – deployed models that provide measurable and purposeful benefit to the organization. Keith will share carefully chosen case studies based upon real world projects that reveal why organizational resistance was a problem and how it was addressed.
- Typical reasons why organizational resistance arises.
- Identifying and prioritizing valid opportunities that align with organizational priorities
- Which teams members should be consulted early in the project design to avoid resistance
- How to estimate ROI during the design phases and achieve ROI in the validation phase
- The importance of a ‘dress rehearsal’ prior to going live.
Word ook een koploper met AI en BI in een dynamisch data landschap
Business teams verhogen de lat voor Business Intelligence en Datawarehouse ondersteuning. BI-competentiecentra en data manager moeten reageren op steeds uitgebreidere vereisten: meer gegevens, meer inzicht, maximale kwaliteit en nauwkeurigheid, zorgvuldige data governance, etc.
Lees meer
Business teams verhogen de lat voor Business Intelligence en Datawarehouse ondersteuning. BI-competentiecentra en data manager moeten reageren op steeds uitgebreidere vereisten: meer gegevens, meer inzicht, maximale kwaliteit en nauwkeurigheid, zorgvuldige data governance, etc. De belofte van nieuwe technologieën zoals Artificial Intelligence trekt steeds meer aandacht en interesse en stimuleert datagedreven innovatie en een versnelde ontwikkeling van slimmere applicaties. Data Scientist-teams groeien en kunnen de leiding overnemen van BI-competentiecentra.
– Hoe moeten dergelijke ontwikkelingen, die logisch zijn vanuit het oogpunt van bedrijfsverbetering, worden ondersteund door data management activiteiten?
– Hoe de privacy te waarborgen en een effectieve strategie voor data-governance te creëren?
– Het wordt een grotere uitdaging om geschikte datawarehouses, BI-functionaliteit en data access controle te ontwerpen wanneer bedrijfsbelangen vaker veranderen en applicatie ontwikkeling gestimuleerd wordt door “AI initiatieven”.
In deze sessie bespreekt Peter technieken en technologie voor effectief (meta) gegevensbeheer en gegevensverwerking voor meer divers wordende data landschappen. Ook een passende governance-aanpak die geavanceerde functies van Business Intelligence en Insight Exploration ondersteunt, zal aan bod komen.
Lees minderData Warehousing in Today and Beyond
The world of data warehousing has changed! With the advent of Big Data, Streaming Data, IoT, and The Cloud, what is a modern data management professional to do? This talk will endeavor to cut through the hype and the buzzword bingo to help you figure out what part of this is helpful.
Lees meer
The world of data warehousing has changed! With the advent of Big Data, Streaming Data, IoT, and The Cloud, what is a modern data management professional to do? It may seem to be a very different world with different concepts, terms, and techniques. Or is it? Lots of people still talk about having a data warehouse or several data marts across their organization. But what does that really mean today? How about the Corporate Information Factory (CIF), the Data Vault, an Operational Data Store (ODS), or just star schemas? Where do they fit now (or do they)? And now we have the Extended Data Warehouse (XDW) as well. How do all these things help us bring value and data-based decisions to our organizations? Where do Big Data and the Cloud fit? Is there a coherent architecture we can define? This talk will endeavor to cut through the hype and the buzzword bingo to help you figure out what part of this is helpful. I will discuss what I have seen in the real world (working and not working!) and a bit of where I think we are going and need to go in today and beyond.
- What are the traditional/historical approaches
- What have organizations been doing recently
- What are the new options and some of their benefits.
Maak uw BI-project succesvol met Data-Driven Storytelling
Al jaren bestaat de wereld van Business Intelligence (BI) uit het bouwen van rapporten en dashboards. Echter, de BI-wereld om ons heen verandert snel. In deze sessie gaan we in op de veranderende BI-wereld en over de toepassing van data-driven storytelling binnen BI-projecten.
Lees meer
Al jaren bestaat de wereld van Business Intelligence (BI) uit het bouwen van rapporten en dashboards. De BI-wereld om ons heen verandert echter snel. (Statistical) Analytics worden meer en meer ingezet, elke student krijgt gedegen R-training en het gebruik van data verplaatst zich van IT naar business. Maar zijn we wel klaar voor deze nieuwe werkwijze? Zijn we in staat om de nieuw verkregen inzichten te delen? En kunnen we echt het onderbuikgevoel van het management veranderen?
Tijdens deze presentatie gaan we in op deze veranderende wereld. We gaan in op hoe we het data-driven storytelling proces kunnen toepassen binnen BI-projecten, welke rollen zijn hiervoor nodig en u krijgt handvatten om nieuw verkregen inzichten te communiceren via storytelling.
• Inzicht in het Data-driven storytelling process
• Visuele data exploratie
• Organisatorische wijzigingen
• Communiceren via Infographics
• Combineren van data, visualisatie en een verhaal.
Lunchpauze
Data Quality & BI/DW – Not yet a marriage made in heaven
Our industry is littered with failed BI/DW projects, with an inability to resolve underlying data quality issues often cited as a primary reason for failure. This presentation tackles these issues and suggests how BI/DW and data quality can and must support each other.
Lees meer
The close links between data quality and business intelligence & data warehousing (BI/DW) have long been recognised. Their relationship is symbiotic. Robust data quality is a keystone for successful BI/DW; BI/DW can highlight data shortcomings and drive the need for better data quality. A key driver for the invention of data warehouses was that they would improve the integrity of the data they store and process.
Despite this close bond between these data disciplines, their marriage has not always been a successful one. Our industry is littered with failed BI/DW projects, with an inability to tackle and resolve underlying data quality issues often cited as a primary reason for failure. Today many analytics and data science projects are also failing to meet their goals for the same reason.
Why has the history of BI/DW been plagued with an inability to build and sustain the solid data quality foundation it needs? This presentation tackles these issues and suggests how BI/DW and data quality can and must support each other. The Ancient Greeks understood this. We must do the same.
This session will address:
- What is data quality and why is it the core of effective data management?
- What can happen when it goes wrong – business and BI/DW implications
- The synergies between data quality and BI/DW
- Traditional approaches to tackling data quality for DW / BI
- The shortcomings of these approaches in today’s BI/DW world
- New approaches for tackling today’s data quality challenges
- Several use cases of organisations who have successfully tackled data quality & the key lessons learned.
De nieuwe business intelligence wereld: van Batch naar Lambda en Kappa
Deze presentatie gaat in op Kappa architecturen. Wat zijn de voor- en nadelen van het verwerken van data langs deze architectuur ten opzichte van de oude batch verwerking of de tussentijdse lambda architectuur? Dit en meer vragen zullen in deze sessie beantwoord worden.
Lees meer
Met de komst van cloud computing is het mogelijk geworden om data sneller te verwerken en infrastructuur mee te laten schalen met de benodigde opslag en cpu capaciteit. Waar voorheen batch computing de norm was en grote datawarehouses werden ontwikkeld, zien we een transitie naar data lakes en real-time verwerking. Eerst kwam de lambda architectuur die naast de batch processing een streaming processing layer toevoegde. En sinds 2014 zien we dat de kappa architectuur de batch processing layer uit de lambda architectuur helemaal weglaat.
Deze presentatie gaat in op Kappa architecturen. Wat zijn de voor- en nadelen van het verwerken van data langs deze architectuur ten opzichte van de oude batch verwerking of de tussentijdse lambda architectuur? Dit vraagstuk zal worden behandeld aan de hand van ervaringen bij KPN met een product gebaseerd op een Kappa architectuur: de Data Services Hub.
Centraal bij de beantwoording staan de aspecten die tegenwoordig worden toebedeeld aan innovatieve technologieën: homogenisatie en ontkoppeling, modulariteit, connectiviteit, programmeerbaarheid en het kunnen profiteren van ‘gebruikers’ sporen.
- Creëren van informatie en kennis uit data
- Hoe verhouden dashboarding en machine-learning in een streaming context zich ten opzichte van de oude meer bekende batch processing way of working?
- Wat betekenen MQTT, Pulsar, Spark en Flink?
- De waarde van centrale pub-sub message bussen, zoals Kafka of Rabbit MQ.
Naar het volgende niveau in automatisering van data management
De automatisering van data management naar een hoger plan tillen is waar het in deze sessie om draait. Samen met klanten snel nieuwe bouwblokken ontwikkelen en toevoegen op basis van patronen vormt de kern van Quipu release 4.
Lees meer
Volgend op haar succesvolle voorganger verheugen wij ons op de release van Quipu 4.0. We brengen zaken een stap verder door een hoger niveau in automatisering van data management te introduceren, waarbij patronen als uitgangspunt worden gehanteerd. Daarmee kan de implementatie van datawarehouses, data migraties, big data toepassingen en soortgelijke projecten veel sneller en makkelijker worden gemaakt. Op het nieuwe platform kunnen samen met klanten snel nieuwe bouwblokken worden ontwikkeld en toegevoegd, waarbij de klantbehoefte leidend is, waar het ontwikkeling betreft. In deze presentatie lichten wij onze visie toe en nodigen wij u uit om deelgenoot te zijn van onze doorontwikkeling.
Lees minderDe uitdagingen van een enterprise data marketplace
Publieke data marketplaces kennen we al heel lang. De laatste jaren is binnen organisaties een variant hiervan in opkomst gekomen: de enterprise data marketplace (ofwel dataloket). In deze sessie wordt behandeld wat de uitdagingen van het ontwikkelen van een eigen enterprise data marketplace is.
Lees meer
Publieke data marketplaces kennen we al heel lang. Het zijn omgevingen die allerlei dataproducten leveren die we kunnen afnemen. De laatste jaren is binnen organisaties een variant hiervan in opkomst gekomen: de enterprise data marketplace (ofwel dataloket). Een EDM is ontwikkeld door de eigen organisatie en levert dataproducten aan interne en externe dataconsumenten. Dataproducten kunnen rapporten zijn, dataservices, datastreams, batch bestanden, enzovoorts. Het essentiële verschil tussen een enterprise datawarehouse en een enterprise data marketplace is dat bij eerstgenoemde de gebruiker wordt gevraagd wat zij nodig hebben en bij de tweede wordt er aangenomen dat de eigenaars weten wat de gebruikers nodig hebben. Ofwel, we gaan van vraag-gedreven naar aanbod-gedreven. Dit klinkt allemaal eenvoudig, maar is dat geheel niet. In deze sessie wordt behandeld wat de uitdagingen van het ontwikkelen van een eigen enterprise data marketplace is.
- Uitdagingen: research, development, marketing, verkopen, betaalwijze
- Is speciale technologie nodig voor het ontwikkelen van een data marketplace?
- Verschillen tussen data warehouses en marketplaces
- Opnemen van een data marketplace in een unified data fabric
- Het belang van een searchable data catalog.
Opening door de dagvoorzitter
Addressing Organizational Resistance to Predictive Analytics and Machine Learning
Many who work within organizations that are in the early stages of their digital transformation are surprised when an accurate model faces organizational resistance. Keith will share case studies based upon real world projects that reveal why organizational resistance was a problem and how it was addressed.
Lees meer
Many who work within organizations that are in the early stages of their digital transformation are surprised when an accurate model — built with good intentions and capable of producing measurable benefit to the organization — faces organizational resistance. No veteran modeler is surprised by this because all projects face some organizational resistance to some degree. This predictable and eminently manageable problem simply requires attention during the project’s design phase. Proper design will minimize resistance and most projects will proceed to their natural conclusion – deployed models that provide measurable and purposeful benefit to the organization. Keith will share carefully chosen case studies based upon real world projects that reveal why organizational resistance was a problem and how it was addressed.
- Typical reasons why organizational resistance arises.
- Identifying and prioritizing valid opportunities that align with organizational priorities
- Which teams members should be consulted early in the project design to avoid resistance
- How to estimate ROI during the design phases and achieve ROI in the validation phase
- The importance of a ‘dress rehearsal’ prior to going live.
Word ook een koploper met AI en BI in een dynamisch data landschap
Business teams verhogen de lat voor Business Intelligence en Datawarehouse ondersteuning. BI-competentiecentra en data manager moeten reageren op steeds uitgebreidere vereisten: meer gegevens, meer inzicht, maximale kwaliteit en nauwkeurigheid, zorgvuldige data governance, etc.
Lees meer
Business teams verhogen de lat voor Business Intelligence en Datawarehouse ondersteuning. BI-competentiecentra en data manager moeten reageren op steeds uitgebreidere vereisten: meer gegevens, meer inzicht, maximale kwaliteit en nauwkeurigheid, zorgvuldige data governance, etc. De belofte van nieuwe technologieën zoals Artificial Intelligence trekt steeds meer aandacht en interesse en stimuleert datagedreven innovatie en een versnelde ontwikkeling van slimmere applicaties. Data Scientist-teams groeien en kunnen de leiding overnemen van BI-competentiecentra.
– Hoe moeten dergelijke ontwikkelingen, die logisch zijn vanuit het oogpunt van bedrijfsverbetering, worden ondersteund door data management activiteiten?
– Hoe de privacy te waarborgen en een effectieve strategie voor data-governance te creëren?
– Het wordt een grotere uitdaging om geschikte datawarehouses, BI-functionaliteit en data access controle te ontwerpen wanneer bedrijfsbelangen vaker veranderen en applicatie ontwikkeling gestimuleerd wordt door “AI initiatieven”.
In deze sessie bespreekt Peter technieken en technologie voor effectief (meta) gegevensbeheer en gegevensverwerking voor meer divers wordende data landschappen. Ook een passende governance-aanpak die geavanceerde functies van Business Intelligence en Insight Exploration ondersteunt, zal aan bod komen.
Lees minderData Warehousing in Today and Beyond
The world of data warehousing has changed! With the advent of Big Data, Streaming Data, IoT, and The Cloud, what is a modern data management professional to do? This talk will endeavor to cut through the hype and the buzzword bingo to help you figure out what part of this is helpful.
Lees meer
The world of data warehousing has changed! With the advent of Big Data, Streaming Data, IoT, and The Cloud, what is a modern data management professional to do? It may seem to be a very different world with different concepts, terms, and techniques. Or is it? Lots of people still talk about having a data warehouse or several data marts across their organization. But what does that really mean today? How about the Corporate Information Factory (CIF), the Data Vault, an Operational Data Store (ODS), or just star schemas? Where do they fit now (or do they)? And now we have the Extended Data Warehouse (XDW) as well. How do all these things help us bring value and data-based decisions to our organizations? Where do Big Data and the Cloud fit? Is there a coherent architecture we can define? This talk will endeavor to cut through the hype and the buzzword bingo to help you figure out what part of this is helpful. I will discuss what I have seen in the real world (working and not working!) and a bit of where I think we are going and need to go in today and beyond.
- What are the traditional/historical approaches
- What have organizations been doing recently
- What are the new options and some of their benefits.
Maak uw BI-project succesvol met Data-Driven Storytelling
Al jaren bestaat de wereld van Business Intelligence (BI) uit het bouwen van rapporten en dashboards. Echter, de BI-wereld om ons heen verandert snel. In deze sessie gaan we in op de veranderende BI-wereld en over de toepassing van data-driven storytelling binnen BI-projecten.
Lees meer
Al jaren bestaat de wereld van Business Intelligence (BI) uit het bouwen van rapporten en dashboards. De BI-wereld om ons heen verandert echter snel. (Statistical) Analytics worden meer en meer ingezet, elke student krijgt gedegen R-training en het gebruik van data verplaatst zich van IT naar business. Maar zijn we wel klaar voor deze nieuwe werkwijze? Zijn we in staat om de nieuw verkregen inzichten te delen? En kunnen we echt het onderbuikgevoel van het management veranderen?
Tijdens deze presentatie gaan we in op deze veranderende wereld. We gaan in op hoe we het data-driven storytelling proces kunnen toepassen binnen BI-projecten, welke rollen zijn hiervoor nodig en u krijgt handvatten om nieuw verkregen inzichten te communiceren via storytelling.
• Inzicht in het Data-driven storytelling process
• Visuele data exploratie
• Organisatorische wijzigingen
• Communiceren via Infographics
• Combineren van data, visualisatie en een verhaal.
Lunchpauze
Data Quality & BI/DW – Not yet a marriage made in heaven
Our industry is littered with failed BI/DW projects, with an inability to resolve underlying data quality issues often cited as a primary reason for failure. This presentation tackles these issues and suggests how BI/DW and data quality can and must support each other.
Lees meer
The close links between data quality and business intelligence & data warehousing (BI/DW) have long been recognised. Their relationship is symbiotic. Robust data quality is a keystone for successful BI/DW; BI/DW can highlight data shortcomings and drive the need for better data quality. A key driver for the invention of data warehouses was that they would improve the integrity of the data they store and process.
Despite this close bond between these data disciplines, their marriage has not always been a successful one. Our industry is littered with failed BI/DW projects, with an inability to tackle and resolve underlying data quality issues often cited as a primary reason for failure. Today many analytics and data science projects are also failing to meet their goals for the same reason.
Why has the history of BI/DW been plagued with an inability to build and sustain the solid data quality foundation it needs? This presentation tackles these issues and suggests how BI/DW and data quality can and must support each other. The Ancient Greeks understood this. We must do the same.
This session will address:
- What is data quality and why is it the core of effective data management?
- What can happen when it goes wrong – business and BI/DW implications
- The synergies between data quality and BI/DW
- Traditional approaches to tackling data quality for DW / BI
- The shortcomings of these approaches in today’s BI/DW world
- New approaches for tackling today’s data quality challenges
- Several use cases of organisations who have successfully tackled data quality & the key lessons learned.
De nieuwe business intelligence wereld: van Batch naar Lambda en Kappa
Deze presentatie gaat in op Kappa architecturen. Wat zijn de voor- en nadelen van het verwerken van data langs deze architectuur ten opzichte van de oude batch verwerking of de tussentijdse lambda architectuur? Dit en meer vragen zullen in deze sessie beantwoord worden.
Lees meer
Met de komst van cloud computing is het mogelijk geworden om data sneller te verwerken en infrastructuur mee te laten schalen met de benodigde opslag en cpu capaciteit. Waar voorheen batch computing de norm was en grote datawarehouses werden ontwikkeld, zien we een transitie naar data lakes en real-time verwerking. Eerst kwam de lambda architectuur die naast de batch processing een streaming processing layer toevoegde. En sinds 2014 zien we dat de kappa architectuur de batch processing layer uit de lambda architectuur helemaal weglaat.
Deze presentatie gaat in op Kappa architecturen. Wat zijn de voor- en nadelen van het verwerken van data langs deze architectuur ten opzichte van de oude batch verwerking of de tussentijdse lambda architectuur? Dit vraagstuk zal worden behandeld aan de hand van ervaringen bij KPN met een product gebaseerd op een Kappa architectuur: de Data Services Hub.
Centraal bij de beantwoording staan de aspecten die tegenwoordig worden toebedeeld aan innovatieve technologieën: homogenisatie en ontkoppeling, modulariteit, connectiviteit, programmeerbaarheid en het kunnen profiteren van ‘gebruikers’ sporen.
- Creëren van informatie en kennis uit data
- Hoe verhouden dashboarding en machine-learning in een streaming context zich ten opzichte van de oude meer bekende batch processing way of working?
- Wat betekenen MQTT, Pulsar, Spark en Flink?
- De waarde van centrale pub-sub message bussen, zoals Kafka of Rabbit MQ.
Naar het volgende niveau in automatisering van data management
De automatisering van data management naar een hoger plan tillen is waar het in deze sessie om draait. Samen met klanten snel nieuwe bouwblokken ontwikkelen en toevoegen op basis van patronen vormt de kern van Quipu release 4.
Lees meer
Volgend op haar succesvolle voorganger verheugen wij ons op de release van Quipu 4.0. We brengen zaken een stap verder door een hoger niveau in automatisering van data management te introduceren, waarbij patronen als uitgangspunt worden gehanteerd. Daarmee kan de implementatie van datawarehouses, data migraties, big data toepassingen en soortgelijke projecten veel sneller en makkelijker worden gemaakt. Op het nieuwe platform kunnen samen met klanten snel nieuwe bouwblokken worden ontwikkeld en toegevoegd, waarbij de klantbehoefte leidend is, waar het ontwikkeling betreft. In deze presentatie lichten wij onze visie toe en nodigen wij u uit om deelgenoot te zijn van onze doorontwikkeling.
Lees minderDe uitdagingen van een enterprise data marketplace
Publieke data marketplaces kennen we al heel lang. De laatste jaren is binnen organisaties een variant hiervan in opkomst gekomen: de enterprise data marketplace (ofwel dataloket). In deze sessie wordt behandeld wat de uitdagingen van het ontwikkelen van een eigen enterprise data marketplace is.
Lees meer
Publieke data marketplaces kennen we al heel lang. Het zijn omgevingen die allerlei dataproducten leveren die we kunnen afnemen. De laatste jaren is binnen organisaties een variant hiervan in opkomst gekomen: de enterprise data marketplace (ofwel dataloket). Een EDM is ontwikkeld door de eigen organisatie en levert dataproducten aan interne en externe dataconsumenten. Dataproducten kunnen rapporten zijn, dataservices, datastreams, batch bestanden, enzovoorts. Het essentiële verschil tussen een enterprise datawarehouse en een enterprise data marketplace is dat bij eerstgenoemde de gebruiker wordt gevraagd wat zij nodig hebben en bij de tweede wordt er aangenomen dat de eigenaars weten wat de gebruikers nodig hebben. Ofwel, we gaan van vraag-gedreven naar aanbod-gedreven. Dit klinkt allemaal eenvoudig, maar is dat geheel niet. In deze sessie wordt behandeld wat de uitdagingen van het ontwikkelen van een eigen enterprise data marketplace is.
- Uitdagingen: research, development, marketing, verkopen, betaalwijze
- Is speciale technologie nodig voor het ontwikkelen van een data marketplace?
- Verschillen tussen data warehouses en marketplaces
- Opnemen van een data marketplace in een unified data fabric
- Het belang van een searchable data catalog.
Agile Datawarehouse Design
Training dimensioneel modelleren door datawarehouse autoriteit Lawrence Corr waarin de nieuwste technieken worden behandeld voor het vergaren van Business Intelligence requirements en het ontwerpen van effectieve datawarehouse- en BI-systemen. Een agile benadering voor dimensioneel modelleren.
Lees meer
Agile techniques emphasise the early and frequent delivery of working software, stakeholder collaboration, responsiveness to change and waste elimination. They have revolutionised application development and are increasingly being adopted by DW/BI teams. This course provides practical tools and techniques for applying agility to the design of DW/BI database schemas – the earliest needed and most important working software for BI.
The course contrasts agile and non-agile DW/BI development and highlights the inherent failings of traditional BI requirements analysis and data modeling. Via class room sessions and team exercises attendees will discover how modelstorming (modeling + brainstorming) data requirements directly with BI stakeholders overcomes these limitations.
Learning objectives
You will learn how to:
- Model BI requirements with BI stakeholders using inclusive tools and visual thinking techniques
- Rapidly translate BI requirements into efficient, flexible data warehouse designs
- Identify and solve common BI problems – before they occur – using dimensional design patterns
- Plan, design and incrementally develop BI solutions with agility
Who Should Attend
- Business and IT professionals who want to develop better BI solutions faster.
- Business analysts, scrum masters, data modelers/architects, DBA’s and application developers, new to DW/BI, will benefit from the solid grounding in dimensional modeling provided.
- Experienced DW/BI practitioners will find the course updates their hard-earned industry knowledge with the latest ideas on agile modeling, data warehouse design patterns and business model innovation.
You receive a free copy of the book Agile Data Warehouse Design by Lawrence Corr.
Programma
Dag 1: Modelstorming – Agile BI Requirements Gathering
Agile Dimensional Modeling Fundamentals
- BI/DW design requirements, challenges and opportunities: the need for agility
- Modeling with BI stakeholders: the case for collaborative data modeling
- Modeling for measurement: the case for dimensional modeling, star schemas, facts & dimensions
- Thinking dimensional using the 7Ws (who, what, when, where, how many, why & how)
- Business Event Analysis and Modeling (BEAM✲): an agile approach to dimensional modeling
Dimensional Modelstorming Tools
- Data stories, themes and BEAM✲ tables: modeling BI data requirements by example
- Timelines: modeling time and process measurement
- Hierarchy charts: modeling dimensional drill-downs and rollups
- Change stories: capturing historical reporting requirements (slowly changing dimension rules)
- Storyboarding the data warehouse design: matrix planning and estimating for agile BI development
- The Business Model Canvas: aligning DW/BI design with business model definition and innovation
- The BI Model Canvas: a systematic approach to BI & star schema design
Dag 2: Agile Star Schema Design
Star Schema Design
- Test-driven design: agile/lean data profiling for validating and improving requirements models
- Data warehouse reuse: identifying, defining and developing conformed dimensions and facts
- Balancing ‘just enough design up front’ (JEDUF) and ‘just in time’ (JIT) data modeling
- Designing flexible, high performance star schemas: maximising the benefits of surrogate keys
- Refactoring star schemas: responding to change, dealing with data debt
- Lean (minimum viable) DW documentation: enhanced star schemas, DW matrix
How Much/How Many: Designing facts, measures and KPIs (Key Performance Indicators)
- Fact types: transactions, periodic snapshots, accumulating snapshots
- Fact additivity: additive, semi-additive and non-additive measures
- Fact performance and usability: indexing, partitioning, aggregating and consolidating facts
Dag 3: Dimensional Design Patterns
Who & What dimension patterns: customers, employees, products and services
- Large populations with rapidly changing dimensional attributes: mini-dimensions & customer facts
- Customer segmentation: business to business (B2B), business to consumer (B2C) dimensions
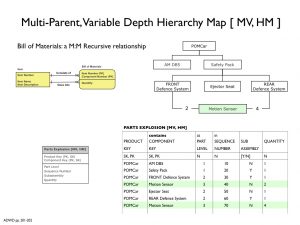
- Recursive customer relationships and organisation structures: variable-depth hierarchy maps
- Current and historical reporting perspectives: hybrid slowly changing dimensions
- Mixed business models: heterogeneous products/services, diverse attribution, ragged hierarchies
- Product and service decomposition: component (bill of materials) and product unbundling analysis
When & Where dimension patterns: dates, times and locations
- Flexible date handling, ad-hoc date ranges and year-to-date analysis
- Modeling time as dimensions and facts
- Multinational BI: national languages reporting, multiple currencies, time zones & national calendars
- Understanding journeys and trajectories: modeling events with multiple geographies
Why & How dimension patterns: cause and effect
- Causal factors: trigging events, referrals, promotions, weather and exception reason dimensions
- Fact specific dimensions: transaction and event status descriptions
- Multi-valued dimensions: bridge tables, weighting factors, impact and ‘correctly weighted’ analysis
- Behaviour Tagging: modeling causation and outcome, dimensional overloading, step dimensions
Putting Machine Learning to Work
Praktische workshop met Keith McCormick over het toepassen van supervised en unsupervised machine learning. Hoe zet je business vraagstukken om in bruikbare machine learning modellen? Welke modellen zijn het meest geëigend voor welke toepassing? Hoe zijn deze modellen op creatieve wijze te combineren? U gaat zelf met oefeningen aan de slag.
Lees meer
Supervised learning lost moderne analytische uitdagingen op en ondersteunt geïnformeerde besluitvorming. Alhoewel het voorspellend vermogen van machinelearning modellen indrukwekkend kan zijn, moet er wel een actie aan gekoppeld zijn om er profijt van te hebben. Modellen moeten daarnaast ook automatisch worden uitgerold om besluitvorming continue te kunnen ondersteunen en meetbare verschillen te realiseren. En hoewel ook unsupervised learning methoden krachtige analytische mogelijkheden bieden is hier vaak nog geen duidelijke route naar productie. Deze cursus laat zien wanneer welke vorm van machinelearning het beste past bij de business doelstellingen en hoe u meerwaarde kunt behalen uit beide benaderingen.
Regressieanalyse, decision trees, neurale netwerken, samen met vele andere supervised learning technieken, realiseren krachtige voorspellende inzichten wanneer historische resultaatwaarden beschikbaar zijn. Zodra deze modellen gebouwd zijn, genereren supervised learning modellen een score die gebruikt kan worden om automatische besluitvorming in organisaties te ondersteunen. Wij zullen verkennen hoe deze bewegende panelen strategisch gezien bij elkaar kunnen worden gebracht.
Unsupervised methoden zoals clusteranalyse, anomaly detectie en associatieregels zijn verkennend van aard en genereren niet zoals supervised learning modellen een voorspellende score. De vraag is hoe deze modellen in staat kunnen worden gesteld om organisatorische besluitvorming te ondersteunen. Deze cursus zal dat laten zien.
Deze cursus laat een verscheidenheid aan voorbeelden zien, te beginnen met het verkennen en interpreteren van modellen en hun toepassing. Mogelijkheden om met de resultaten van deze modellen verder te gaan zullen worden bezien. U zult ook zien hoe een verzameling van modellen, waaronder businessregels, supervised modellen en unsupervised modellen gezamenlijk kunnen worden toegepast in concrete situaties, zoals bij fraudedetectie en het verstrekken van verzekeringen.
Leerdoelen
- Wanneer moet u supervised en wanneer unsupervised modellen toepassen?
- Mogelijkheden om machinelearning in te zetten voor besluitvorming in uw organisatie
- Hoe kunt u verschillende modellen inzetten voor benaderingen en classificaties in de werkelijkheid?
- Effectieve technieken om resultaten van unsupervised learning toe te passen
- Het interpreteren en monitoren van uw modellen voor continue verbeteringen
- Hoe combineert u op creatieve wijze supervised en unsupervised modellen om tot betere resultaten te komen?
Bestemd voor ú
Deze interactieve workshop is opgezet voor Analisten, Data scientists, IT Professionals, BI Professionals, Technology Planners, Consultants, Business analisten en Projectleiders van analyse opdrachten.
Onderwerpen
1. Model Development Introduction
Current Trends in AI, Machine Learning and Predictive Analytics
- Algorithms in the News: Deep Learning
- The Modeling Software Landscape
- The Rise of R and Python: The Impact on Modeling and Deployment
- Do I Need to Know About Statistics to Build Predictive Models?
2. Strategic and Tactical Considerations in Binary Classification
- What’s is an Algorithm?
- Is a “Black Box” Algorithm an Option for Me?
- Issues Unique to Classification Problems
- Why Classification Projects are So Common
- Why are there so many Algorithms?
3. Data Preparation for Supervised Models
- Data Preparation Law
- Integrate Data Subtasks
- Aggregations: Numerous Options
- Restructure: Numerous Options
- Data Construction
- Ratios and Deltas
- Date Math
- Extract Subtask
4. The Tasks of the Model Phase
- Optimizing Data for Different Algorithms
- Model Assessment
- Evaluate Model Results
- Check Plausibility
- Check Reliability
- Model Accuracy and Stability
- Lift and Gains Charts
- Modeling Demonstration
- Assess Model Viability
- Select Final Models
- Why Accuracy and Stability are Not Enough
- What to Look for in Model Performance
- Exercise Breakout Session
- Select Final Models
- Create & Document Modeling Plan
- Determine Readiness for Deployment
- What are Potential Deployment Challenges for Each Candidate Model?
- Evaluate Model Results
5. What is Unsupervised Learning?
- Clustering
- Association Rules
- Why most organizations utilize unsupervised methods poorly
- Case Study 1: Finding a new opportunity
- Case Studies 2, 3, and 4: How do supervised and unsupervised work together
- Exercise Breakout Session: Pick the right approach for each case study
- Data Preparation for Unsupervised
- The importance of standardization
- Running an analysis directly on transactional data
- Unsupervised Algorithms:
- Hierarchical Clustering
- K-means
- Self-Organizing Maps
- K Nearest Neighbors
- Association Rules
- Interpreting Unsupervised
- Exercise Breakout Session: Which value of K is best?
- Choosing the right level of granularity
- Reporting unsupervised results
6. Wrap-up and Next Steps
- Supplementary Materials and Resources
- Conferences and Communities
- Get Started on a Project!
- Options for Implementation Oversight and Collaborative Development
Agile Datawarehouse Design
Training dimensioneel modelleren door datawarehouse autoriteit Lawrence Corr waarin de nieuwste technieken worden behandeld voor het vergaren van Business Intelligence requirements en het ontwerpen van effectieve datawarehouse- en BI-systemen. Een agile benadering voor dimensioneel modelleren.
Lees meer
Agile techniques emphasise the early and frequent delivery of working software, stakeholder collaboration, responsiveness to change and waste elimination. They have revolutionised application development and are increasingly being adopted by DW/BI teams. This course provides practical tools and techniques for applying agility to the design of DW/BI database schemas – the earliest needed and most important working software for BI.
The course contrasts agile and non-agile DW/BI development and highlights the inherent failings of traditional BI requirements analysis and data modeling. Via class room sessions and team exercises attendees will discover how modelstorming (modeling + brainstorming) data requirements directly with BI stakeholders overcomes these limitations.
Learning objectives
You will learn how to:
- Model BI requirements with BI stakeholders using inclusive tools and visual thinking techniques
- Rapidly translate BI requirements into efficient, flexible data warehouse designs
- Identify and solve common BI problems – before they occur – using dimensional design patterns
- Plan, design and incrementally develop BI solutions with agility
Who Should Attend
- Business and IT professionals who want to develop better BI solutions faster.
- Business analysts, scrum masters, data modelers/architects, DBA’s and application developers, new to DW/BI, will benefit from the solid grounding in dimensional modeling provided.
- Experienced DW/BI practitioners will find the course updates their hard-earned industry knowledge with the latest ideas on agile modeling, data warehouse design patterns and business model innovation.
You receive a free copy of the book Agile Data Warehouse Design by Lawrence Corr.
Programma
Dag 1: Modelstorming – Agile BI Requirements Gathering
Agile Dimensional Modeling Fundamentals
- BI/DW design requirements, challenges and opportunities: the need for agility
- Modeling with BI stakeholders: the case for collaborative data modeling
- Modeling for measurement: the case for dimensional modeling, star schemas, facts & dimensions
- Thinking dimensional using the 7Ws (who, what, when, where, how many, why & how)
- Business Event Analysis and Modeling (BEAM✲): an agile approach to dimensional modeling
Dimensional Modelstorming Tools
- Data stories, themes and BEAM✲ tables: modeling BI data requirements by example
- Timelines: modeling time and process measurement
- Hierarchy charts: modeling dimensional drill-downs and rollups
- Change stories: capturing historical reporting requirements (slowly changing dimension rules)
- Storyboarding the data warehouse design: matrix planning and estimating for agile BI development
- The Business Model Canvas: aligning DW/BI design with business model definition and innovation
- The BI Model Canvas: a systematic approach to BI & star schema design
Dag 2: Agile Star Schema Design
Star Schema Design
- Test-driven design: agile/lean data profiling for validating and improving requirements models
- Data warehouse reuse: identifying, defining and developing conformed dimensions and facts
- Balancing ‘just enough design up front’ (JEDUF) and ‘just in time’ (JIT) data modeling
- Designing flexible, high performance star schemas: maximising the benefits of surrogate keys
- Refactoring star schemas: responding to change, dealing with data debt
- Lean (minimum viable) DW documentation: enhanced star schemas, DW matrix
How Much/How Many: Designing facts, measures and KPIs (Key Performance Indicators)
- Fact types: transactions, periodic snapshots, accumulating snapshots
- Fact additivity: additive, semi-additive and non-additive measures
- Fact performance and usability: indexing, partitioning, aggregating and consolidating facts
Dag 3: Dimensional Design Patterns
Who & What dimension patterns: customers, employees, products and services
- Large populations with rapidly changing dimensional attributes: mini-dimensions & customer facts
- Customer segmentation: business to business (B2B), business to consumer (B2C) dimensions
- Recursive customer relationships and organisation structures: variable-depth hierarchy maps
- Current and historical reporting perspectives: hybrid slowly changing dimensions
- Mixed business models: heterogeneous products/services, diverse attribution, ragged hierarchies
- Product and service decomposition: component (bill of materials) and product unbundling analysis
When & Where dimension patterns: dates, times and locations
- Flexible date handling, ad-hoc date ranges and year-to-date analysis
- Modeling time as dimensions and facts
- Multinational BI: national languages reporting, multiple currencies, time zones & national calendars
- Understanding journeys and trajectories: modeling events with multiple geographies
Why & How dimension patterns: cause and effect
- Causal factors: trigging events, referrals, promotions, weather and exception reason dimensions
- Fact specific dimensions: transaction and event status descriptions
- Multi-valued dimensions: bridge tables, weighting factors, impact and ‘correctly weighted’ analysis
- Behaviour Tagging: modeling causation and outcome, dimensional overloading, step dimensions
Putting Machine Learning to Work
Praktische workshop met Keith McCormick over het toepassen van supervised en unsupervised machine learning. Hoe zet je business vraagstukken om in bruikbare machine learning modellen? Welke modellen zijn het meest geëigend voor welke toepassing? Hoe zijn deze modellen op creatieve wijze te combineren? U gaat zelf met oefeningen aan de slag.
Lees meer
Supervised learning lost moderne analytische uitdagingen op en ondersteunt geïnformeerde besluitvorming. Alhoewel het voorspellend vermogen van machinelearning modellen indrukwekkend kan zijn, moet er wel een actie aan gekoppeld zijn om er profijt van te hebben. Modellen moeten daarnaast ook automatisch worden uitgerold om besluitvorming continue te kunnen ondersteunen en meetbare verschillen te realiseren. En hoewel ook unsupervised learning methoden krachtige analytische mogelijkheden bieden is hier vaak nog geen duidelijke route naar productie. Deze cursus laat zien wanneer welke vorm van machinelearning het beste past bij de business doelstellingen en hoe u meerwaarde kunt behalen uit beide benaderingen.
Regressieanalyse, decision trees, neurale netwerken, samen met vele andere supervised learning technieken, realiseren krachtige voorspellende inzichten wanneer historische resultaatwaarden beschikbaar zijn. Zodra deze modellen gebouwd zijn, genereren supervised learning modellen een score die gebruikt kan worden om automatische besluitvorming in organisaties te ondersteunen. Wij zullen verkennen hoe deze bewegende panelen strategisch gezien bij elkaar kunnen worden gebracht.
Unsupervised methoden zoals clusteranalyse, anomaly detectie en associatieregels zijn verkennend van aard en genereren niet zoals supervised learning modellen een voorspellende score. De vraag is hoe deze modellen in staat kunnen worden gesteld om organisatorische besluitvorming te ondersteunen. Deze cursus zal dat laten zien.
Deze cursus laat een verscheidenheid aan voorbeelden zien, te beginnen met het verkennen en interpreteren van modellen en hun toepassing. Mogelijkheden om met de resultaten van deze modellen verder te gaan zullen worden bezien. U zult ook zien hoe een verzameling van modellen, waaronder businessregels, supervised modellen en unsupervised modellen gezamenlijk kunnen worden toegepast in concrete situaties, zoals bij fraudedetectie en het verstrekken van verzekeringen.
Leerdoelen
- Wanneer moet u supervised en wanneer unsupervised modellen toepassen?
- Mogelijkheden om machinelearning in te zetten voor besluitvorming in uw organisatie
- Hoe kunt u verschillende modellen inzetten voor benaderingen en classificaties in de werkelijkheid?
- Effectieve technieken om resultaten van unsupervised learning toe te passen
- Het interpreteren en monitoren van uw modellen voor continue verbeteringen
- Hoe combineert u op creatieve wijze supervised en unsupervised modellen om tot betere resultaten te komen?
Bestemd voor ú
Deze interactieve workshop is opgezet voor Analisten, Data scientists, IT Professionals, BI Professionals, Technology Planners, Consultants, Business analisten en Projectleiders van analyse opdrachten.
Onderwerpen
1. Model Development Introduction
Current Trends in AI, Machine Learning and Predictive Analytics
- Algorithms in the News: Deep Learning
- The Modeling Software Landscape
- The Rise of R and Python: The Impact on Modeling and Deployment
- Do I Need to Know About Statistics to Build Predictive Models?
2. Strategic and Tactical Considerations in Binary Classification
- What’s is an Algorithm?
- Is a “Black Box” Algorithm an Option for Me?
- Issues Unique to Classification Problems
- Why Classification Projects are So Common
- Why are there so many Algorithms?
3. Data Preparation for Supervised Models
- Data Preparation Law
- Integrate Data Subtasks
- Aggregations: Numerous Options
- Restructure: Numerous Options
- Data Construction
- Ratios and Deltas
- Date Math
- Extract Subtask
4. The Tasks of the Model Phase
- Optimizing Data for Different Algorithms
- Model Assessment
- Evaluate Model Results
- Check Plausibility
- Check Reliability
- Model Accuracy and Stability
- Lift and Gains Charts
- Modeling Demonstration
- Assess Model Viability
- Select Final Models
- Why Accuracy and Stability are Not Enough
- What to Look for in Model Performance
- Exercise Breakout Session
- Select Final Models
- Create & Document Modeling Plan
- Determine Readiness for Deployment
- What are Potential Deployment Challenges for Each Candidate Model?
- Evaluate Model Results
5. What is Unsupervised Learning?
- Clustering
- Association Rules
- Why most organizations utilize unsupervised methods poorly
- Case Study 1: Finding a new opportunity
- Case Studies 2, 3, and 4: How do supervised and unsupervised work together
- Exercise Breakout Session: Pick the right approach for each case study
- Data Preparation for Unsupervised
- The importance of standardization
- Running an analysis directly on transactional data
- Unsupervised Algorithms:
- Hierarchical Clustering
- K-means
- Self-Organizing Maps
- K Nearest Neighbors
- Association Rules
- Interpreting Unsupervised
- Exercise Breakout Session: Which value of K is best?
- Choosing the right level of granularity
- Reporting unsupervised results
6. Wrap-up and Next Steps
- Supplementary Materials and Resources
- Conferences and Communities
- Get Started on a Project!
- Options for Implementation Oversight and Collaborative Development
Tijdgebrek?
Heeft u slechts één dag de tijd om de DW&BI Summit te bezoeken? Maak een keuze uit de onderwerpen en kom op alleen 27 maart of op 28 maart. Het is namelijk ook mogelijk om alleen de eerste dag van het congres of alleen de tweede dag te bezoeken. De onderwerpen zijn zodanig gekozen dat zij op zich zelf staan zodat het ook mogelijk is om dag twee te volgen zonder dat u dag één heeft bijgewoond.
Sprekers
Alec Sharp
Nicola Askham
Jos van Dongen
Remco Broekmans
Tanja Ubert
Exposanten en Mediapartners


 @AdeptEventsNL
@AdeptEventsNL